- 股票掌故
- 香港股票資訊
- 神州股票資訊
- 台股資訊
- 博客好文
- 文庫舊文
- 香港股票資訊
- 第一財經
- 微信公眾號
- Webb哥點將錄
- 港股專區
- 股海挪亞方舟
- 動漫遊戲音樂
- 好歌
- 動漫綜合
- RealBlog
- 測試
- 強國
- 潮流潮物 [Fashion board]
- 龍鳳大茶樓
- 文章保管庫
- 財經人物
- 智慧
- 世界之大,無奇不有
- 創業
- 股壇維基研發區
- 英文
- 財經書籍
- 期權期指輪天地
- 郊遊遠足
- 站務
- 飲食
- 國際經濟
- 上市公司新聞
- 美股專區
- 書藉及文章分享區
- 娛樂廣場
- 波馬風雲
- 政治民生區
- 財經專業機構
- 識飲色食
- 即市討論區
- 股票專業討論區
- 全球政治經濟社會區
- 建築
- I.T.
- 馬後砲膠區之圖表
- 打工仔
- 蘋果專欄
- 雨傘革命
- Louis 先生投資時事分享區
- 地產
Random Tags
一線投資人如何評估人工智能初創公司?
來源: http://www.iheima.com/zixun/2017/0221/161364.shtml

人工智能是否是公司的核心價值主張?
本文由IT桔子(微信ID:itjuzi521)授權i黑馬發布。
作者 Mariya Yao,聊天機器人公司TOPBOTS研究和設計主管。作者采訪了高通投資部、CRV、IA Ventures、Two Sigma 等頂級風投公司的資深投資人,來了解這些成功的投資人是如何看待和評估人工智能創業公司的,以下是全文。

人工智能是否是公司的核心價值主張?
高通投資部的Varun Jain表示 ,許多融不到資的公司將自己定位為人工智能公司。他曾經見過公司打著人工智能Wifi、人工智能榨汁機等等各種各樣的名號。
人工智能對於這些公司只是一個附加的功能,而不是公司的核心價值主張。 傳統的Wi-Fi路由器可以使用人工智能方法來檢測網絡數據中的異常,並標記那些錯誤,但這個功能並不能明顯改變或提高附加值。高通風投部投資了Clarifai和Cruise Automation(已被通用收購)。 Cruise是一家提供自動駕駛系統的公司, Clarifai 是一家獨立的圖像識別初創公司,在成立三年多的時間里率先將圖形識別從靜態圖片帶入了接近實時的級別,同時也收獲了為數不少的企業客戶。
技術團隊是否可靠?
傑出的人工智能技術公司通常擁有來自知名研究中心或者Google Brain、Facebook人工智能團隊等公司的成員。
機器人公司 iRobot的創始人Rod Brooks是MIT人工智能實驗室的創始主管。Jibo的創始人Cynthia Breazea在MIT成立了個人機器人小組,是一位世界知名的社交機器人專家。Pullstring的CEO Oren Jacob曾經是皮克斯的CTO,自公司成立初期就與喬布斯一起工作。
在現階段的人工智能行業,只有少數擁有在大公司或頂尖大學的經驗的AI專家能夠構建真正創新的解決方案,如果一個團隊的產品解決方案需要的AI技術與團隊不匹配,這將會引起質疑。

是否解決客戶願意付費的難題?
當CEO不停地強調公司的人工智能技術,而不是客戶的需求時,投資人的興趣就會降低。投資人投的是有價值的產出,而不是科研項目。我們接觸到的所有投資人都對這個觀點表示贊同。
“如果必須做個選擇,我認為領域專業知識勝過機器學習專業知識。” IA Ventures的Brad Gillespie說,IA Ventures投資了網絡安全公司Vectra Networks,專註於解決重要的客戶問題,並最大限度幫助安全分析師。
Vectra的一家競爭對手公司向客戶強調他們複雜的機器智能,但買方的反饋是這些家夥很聰明,但他們並不理解我的業務。他們的產品有很多的專業術語,但我不明白它是什麽。
有效解決業務問題不僅需要技術方法,而且還要專註於特定的業務領域。解決困難的問題需要使用不同的技術,但是在垂直領域人工智能減少了這種複雜性。
是否擁有相關的、專有的和可擴展的數據源?
你的數據來源是什麽?你是否依靠大公司提供數據,或者有獨立的收集方式?這兩種方法都是可行的,但是具有獨立收集方式往往更受歡迎。
自動駕駛汽車通常在郊區、停車場和不反映現實駕駛的封閉環境中進行測試。高通投資的公司Cruise Automation由專業人員監控,在城市環境中操作測試車輛,從而獲取了許多缺失的關鍵數據。高通投資的另一家人工智能公司Clarifai開始與一個流行的消費級app進行合作,使其在進一步進行擴展到特定業務數據之前,能夠獲得獨特的眾包數據。
除了有獨有的數據源,他們還必須解決相關的挑戰。下一代人工智能取決於你挖掘數據的複雜性。非結構化圖像,視頻和音頻數據比文本更難挖掘。還需要考慮企業是否使用快速移動的數據或靜態數據,快速移動的數據的算法,如實時圖像處理的自駕車汽車,往往複雜得多。最後,團隊必須證明他們有能力基於獨特的數據不斷提高他們的表現。定期檢查團隊是否能夠展示快速處理數據和有效優化技術的能力,使系統越來越可靠。
構建了獨有的自主技術還是依靠開源的框架?
企業是利用公開源代碼的框架還是研發自主技術往往是很多投資人考察的一項重要標準。 使用公開源代碼可以讓你分析一些表面的數據,但不太可能達到解決困難商業難題所需的水平。
DCM的投資團隊依靠強大的行業顧問和技術專家網絡幫助審查技術棧、數據架構,並確定企業是否以合理的方法進行數據收集、存儲、解析或註釋,他們也幫助識別出騙子公司。

是否有一個高粘性的產品?
如果為客戶帶來至少5-10倍的效率提升,作為一家新的公司,僅僅依靠這一點,你很難讓客戶看到你的價值所在,創業者應該考慮給客戶帶來收入。比如,如果你把人工智能應用到客戶的招聘流程當中,先問問你自己,如果我能夠帶來5倍的效率提升,招聘到的人是否能夠為客戶的公司帶來100倍的收入提升?
此外,任何的價值提升必須要能夠傳遞到客戶。以一種客戶可以消費的形式,比如儀表盤或者或可操作的洞見。即使你有一個具有吸引力的產品,僅僅靠單個產品來抓住客戶並不是一個可行的業務,你應該尋求多樣化的收入和多元化的客戶,經常問自己這兩個問題:你的收入是否在增長,客戶是否成為老客戶?你的客戶是否想要新的、更多的解決方案?
是否擁有多樣化的團隊?
最後一點,但並非最不重要,投資人尋找的是一個多樣化的團隊,成功的公司需要有各個領域的專家,包括行業、商務、銷售,而不只是技術團隊。技術AI團隊與銷售人員之間能不能很好的配合,投資人尋找的是一個經驗豐富的、擁有成熟履歷的AI創始人或者是互補的團隊。銷售和營銷往往被註重技術的人工智能創業公司忽視,但是它們對於成功非常重要。AI創業公司最大錯誤是在營銷方面做的不夠,大多數客戶並不知道自己需要這些產品。


 匿名用戶
匿名用戶
在讓圍棋漸失樂趣之後,人工智能要將翻譯行業變天
來源: http://www.iheima.com/zixun/2017/0221/161349.shtml

人類的翻譯水平很難繼續提高了,但是機器的翻譯水平只會一代優於一代,沒有必要去打一場沒有勝算的仗。
本文由闌夕(微信ID:techread)授權i黑馬發布。
與趨勢做對,是最愚蠢的事情。
就像工業革命前夜的紡織女工或是馬車車夫,精進技藝已經毫無意義,對於科技發展的反對,也只是徒增疲勞。
這同時也構成了進步的代價,非線性的變革速度,讓十八世紀以來的三百年,前所未有的重塑了全球的運行法則,人類亦需要迫使自己跟上時代的步履,生存和適應新的世界。

而在Google的技術總監同時也是未來學家Ray Kurzweil看來,技術爆炸不會戛然而止,基礎學科的完善和應用市場的壯大,將會維持倍增效應,「二十一世紀所取得的進步,最終可以達到二十世紀的一千倍。」
也正是基於這種樂觀,學術業界普遍警惕人工智能的進展,包括霍金在內的科學巨擘頻頻呼籲建立人工智能在生產力方面的準則,用以防範在大規模富裕到來之前的大規模失業。
可惜「口嫌體正直」也是學者們的本性,潘多拉的魔盒一旦被打開,誰也無法克制「朝聞道,夕可死矣」的誘惑。
2012年,麻省理工學院(MIT)人工智能實驗室博士後、新墨西哥大學終身副教授Terran Lane向校方交辭呈,決定加入Google。
Terran Lane在其個人博客寫了一篇公開信,講述他離開學院投奔企業的原因:
「改變世界的機會,愈來愈向掌握尖端技術能力的企業集中,而大學的教授們,卻要受制於科研資金的天花板,難以申請具有探索性和交叉性的項目。」
而在賓夕法尼亞州的卡內基梅隆大學,其機器人研究中心的一百余名教授僅在2016年就有超過四十人被Uber挖走,在校內的留言板上,有教授如此抱怨:「我甚至留不住自己的研究生。沒等他們畢業,企業就想挖人。」
一半海水,一半火焰。
人工智能的所謂「威脅論」無論是否遭到誇大,這塊位於山巔的巨石都已離開它的原始位置,開始緩緩向下滾動,而率先遭殃的,總是最為接近既定軌道的生物。
比如,網易有道剛剛發布的「有道人機翻譯」服務,就將筆譯這個搖搖欲墜的職業更進一步的推向了深淵。
長期以來,翻譯都是一項智力工作,許多優秀的作家——比如歌德、伯爾、魯迅——同時也都是翻譯家,翻譯能力亦對文學作品的全球化傳播有著極大的影響,村上春樹就被戲稱有著林少華和施小煒兩個版本的面貌,而劉慈欣的《三體》斬獲雨果獎,同為科幻作家的華裔譯者劉宇昆就被公認為功不可沒。
只是,在真正的交易市場上,翻譯服務的貶值並非是在朝夕之間所發生的,一名從事筆譯工作超過二十年的高級翻譯員在知乎上直言同行需要盡快另尋發展道路,因為「人類的翻譯水平很難繼續提高了,但是機器的翻譯水平只會一代優於一代,沒有必要去打一場沒有勝算的仗。」
再來看看,網易有道捅出的這柄寒刀。
區別於免費的機器翻譯服務,網易有道早在2011年,接入了付費的人工翻譯,一端連接有著文稿翻譯需求的用戶,一端連接具有翻譯資質的專業譯員,自由撮合,按量計價。
擊穿人力成本底線的,永遠都是自動化的工業產品。
網易有道的人機翻譯服務,是將翻譯程序進行重構,粗譯由其自主研發的神經網絡翻譯技術(YNMT)完成,譯員在成稿之後介入進行譯後編輯(PE)、校對和潤色,相比人工翻譯的「高質高價的翻譯結果」,人機翻譯提供的是「優質低價的翻譯結果」。

事實上,並不是所有的翻譯需求,都要匹配一個大師級的譯者,就像如果只在電腦上玩玩掃雷遊戲,就不需要在顯卡性能上投入過剩。
網易自家的跨境電商平臺「考拉海購」就是「有道人機翻譯」的客戶之一,面對海量的海外商品介紹,翻譯的質量要求就是準確達意四字,使用專業的人工翻譯,不如選擇半價的人機翻譯,在成本規模上起到節省作用。
丁磊若是聽聞自己精打細算的精神在公司上下貫徹得如此到位,不知是否心生欣慰。
根據Google提交的論文顯示,使用神經網絡解決機器翻譯的「人味」問題已為科技公司打開通向光明之門,相比傳統機器翻譯的分詞翻譯原理——也就是拆解長句逐詞翻譯——神經網絡技術能夠自我學習大量的語言模型,從而將詞組進行整體的理解和轉化。
就像「I can can a can with a can」這個句子,使用機器翻譯的結果是慘不忍睹的,但是調教得當的神經網絡卻可以識別同一個單詞的助動詞、動詞、名詞等不同詞性,並自動調整語序,強力提升正確率。
據說「有道人機翻譯」在部分領域——比如新聞和詞典這類特定書面語料的翻譯上——的BLEU值甚至超過了Google,這對網易有道的團隊是相當大的鼓舞。
去年年底,曾和網易有道的CEO周楓有過一次交流,他亦提到過團隊在人工智能及機器學習方面的重金投入,「在這方面的下潛深度,將會直接兌換未來的市場回報。」
周楓對於人工智能的態度,似乎也能代表科技行業的普遍情緒:他堅信人工智能的前景無量,卻又始終尊重高級人力的價值,前者的「攬活」越多,後者的不可取代性也就越高。
所以他也更願意用「改變」而非「更替」來定義網易有道在翻譯行業的這場動作,這個世界上還有太多的上層翻譯市場亟待打開——比如文化內容的跨國交流和文藝作品的翻譯引進——優秀的翻譯從業者不必拘泥於去和機器爭搶「粗活」,而是開拓那些真正需要智慧交互的「細活」。
2012年的時候,周楓在新浪微博回應一名用戶關於「有道詞典的翻譯太偏中式英語」的反饋時,他的回答是這樣的:
「目前機器翻譯的確比較生硬,語言的準確理解的靈活應用,到目前為止還是人類的專長啊,期待技術突破的到來。與此同時,我們的工程師在努力想各種新穎的辦法輔助翻譯,請期待。」
時間最終證明,周楓的回複並無虛情,足足用了五年時間——或者說僅僅用了五年時間——他和他的團隊終於為用戶獻上了解決方案。
如果創新有其捷徑,也無非就是堅持二字罷了。
無論如何,科技進化的風險仍然值得註意,當美國這個全球最強大的國家也開始強調「要為國民創造工作崗位」,所有人都應當意識到這個經濟議題委實並沒有那麽宏觀,而學無止境的競爭,則將鞭笞著人們不斷前行,在和同類或是異類的競技場上爭取勝利,則是亙古不變的主旋律。
古羅馬詩人奧維德是這樣說的:「弓若不張,即盡失其力。」
 匿名用戶
匿名用戶
谷歌推出人工智能工具助新聞媒體篩查惡意言論
2月24日消息,據英國《金融時報》報道,谷歌推出了一款人工智能工具,可以識別網上的辱罵評論,幫助出版商回應要求它們遏止仇恨言論的日益增大的壓力。
這款免費谷歌軟件名為Perspective,正得到一系列新聞機構的測試,包括《紐約時報》、《衛報》、《經濟學人》,作為幫助簡化人工審核其文章下面的評論的一種方式。
“新聞機構希望鼓勵與其內容相關的參與和討論,但發現要篩查數以百萬計的評論,甄別其中的惡意挑釁或辱罵言論需要耗費大量財力、人力以及時間。”研發這款工具的谷歌科技孵化器Jigsaw總裁賈里德·科恩表示。“其結果是,很多網站徹底關閉了評論功能。但他們告訴我們這不是他們想要的解決辦法。”
目前,該軟件供谷歌“數字新聞行動”涵蓋的一系列出版商使用,包括英國廣播公司、英國《金融時報》、《回聲報》和《新聞報》,同時在理論上可供YouTube、Twitter和Facebook等第三方社交媒體平臺使用。
“從小開發者到互聯網上的最大平臺,我們對與各方合作持開放態度。我們都有共享利益,並受益於健康的網上討論。”Jigsaw的產品經理CJ·亞當斯表示。
Perspective幫助更快地甄別辱罵評論,以便人工審核。該算法經過了數十萬條在維基百科(Wikipedia)和《紐約時報》等網站上被人工審核者貼上“有毒”標簽的用戶評論的訓練。
它的工作原理是基於在線評論與被貼上“有毒”標簽的評論的相似度,或這些評論使別人離開對話的可能性,對其進行打分。
“我們都很熟悉網上評論與日俱增的毒性,”科恩表示,“人們因為這一點而離開對話,我們希望賦予出版商力量,能夠重新贏回這些人。”
斯坦福大學實現高性能低功耗人工突觸,可用於神經網絡計算
來源: http://www.iheima.com/zixun/2017/0224/161469.shtml

或許有一天,這款突觸能夠成為一臺更接近大腦計算機的一部分,它特別有利於處理視覺、聽覺信號的計算過程。
本文由機器之心(微信 ID: almosthuman2014)授權i黑馬發布。
盡管這些年來,計算機技術取得不少進展,但是,在再造大腦低能耗、簡潔的信息處理過程這方面,我們仍然步履蹣跚。現在,斯坦福大學和桑迪亞國家實驗室的研究人員取得了重要進展,該研究可以幫助計算機模擬某塊大腦高效設計,亦即人工突觸。

Alberto Salleo,材料科學與工程學副教授,研究生 Scott Keene 在確知用於神經網絡計算的人工突觸的電化學性能。他們是創造這一新設備團隊的成員。
Alberto Salleo 說,它運行起來就像是真的突觸,不過,它是一個可以制造出來的電子設備。Alberto Salleo 是斯坦福大學材料科學與工程學副教授,也是這篇論文的資深作者(senior author)。「這是一套全新的設備系列,之前並沒有看到過這類架構。許多關鍵標準測評後,我們發現,這款設備的性能要比其他任何非有機設備要好。」
相關研究發表在了 2 月 20 日 的 Nature Materials上,該人工突觸模仿了大腦突觸從通過其中的信號中進行學習的方式。較之傳統計算方式,這種方式要節能得多,傳統方法通常分別處理信息然後再將這些信息存儲到存儲器中。就是在這里,處理過程創造出記憶。
或許有一天,這款突觸能夠成為一臺更接近大腦計算機的一部分,它特別有利於處理視覺、聽覺信號的計算過程。比如,聲控接口以及自動駕駛汽車。過去,這一領域已經研究出人工智能算法支持下的高效神經網絡,但是,這些模仿者距離大腦仍然比較遙遠,因為,它們還依賴傳統的能耗計算機硬件。
建造一個大腦
人類學習時,電子信號會在大腦神經元之間傳遞。首次橫穿神經元最耗費能量。再往後,連接所需的能力就少了。這也是突觸為學習新東西、記住已學內容創造便利條件的方式。人工突觸,和所有其他類腦計算版本不同,可以同時完成(學習和記憶)這兩項任務,並能顯著節省能量。
深度學習算法非常強大,不過,仍然依賴處理器來計算、模擬電子狀態並將其保存在某個地方,就能耗和時間而言,這可不夠高效,Yoeri van de Burgt 說,他之前是 Salleo lab 的博士後研究人員(postdoctoral scholar),也是這篇論文的第一作者。「我們沒有模擬一個神經網絡,而是試著制造一個神經網絡。」
這款人工突觸是以電池設計為基礎的。由兩個靈活的薄膜組成,薄膜帶有三個終端,這些終端通過鹽水電解質連接起來。它的功能就像一個晶體管,其中一個終端控制其與其他兩個終端之間的電流。
就像大腦中的神經通路可以通過學習得到加強,研究人員通過重複放電、充電,為人工突觸編程。訓練後,他們就能預測(不確定性僅為 1%)需要多少伏電,才能讓突觸處於某種特定電信號狀態(electrical state),而且一旦抵達那種狀態,它就可以保持該狀態。易言之,不同於普通電腦,關掉電腦前,你會先將工作保存在硬件上,人工突觸能回憶起它的編程過程而無需任何其他操作或部件。
測試人工突觸網絡
桑迪亞國家實驗室的研究者目前只制造了一個人工神經突觸,但是,他們使用有關突觸實驗中獲得的 15,000 個測量結果來模擬某一列(array)突觸在神經網絡中的運行方式。他們測試了模擬網絡識別手寫數字 0 到 9 的能力。三個數據集上的測試結果顯示其識別手寫數字準確度達 93%~97%。
盡管這項工作對於人類來說顯得相對簡單,但是對於傳統計算機而言,要解釋視覺與聽覺信號曾經是非常困難的。
「我們期望計算設備能做的工作越來越多,這就需要模擬大腦工作方式的計算方式,因為用傳統計算來完成這些工作,能耗巨大,」A. Alec Talin 說,「我們已經證實這款設備很適合實現這些算法,而且很節能。」A. Alec Talin 是桑迪亞國家實驗室的傑出技術研究員,也是這篇論文的資深作者。
該設備極其適合於傳統計算機執行起來很費勁的信號識別和分類工作。數字晶體管只能處於兩種狀態,比如 0 或 1,但是研究人員在一個人工突觸上成功編碼了 500 種狀態,對於神經元類計算模型來說,這很有用。從一種狀態切換到另一種狀態所使用的能耗約為當前最先進計算系統的 1/10,最先進的計算系統需要這些能耗將數據從處理單元移動到存儲器。
然而,較之一個生物突觸引發放電所需的最低能耗,這款人工突觸仍然不夠節能,所需能耗是前者的 10000 倍。研究人員希望,一旦他們測試用於更小的設備的人工神經突觸,他們可以實現類似生物神經元級別的能耗水平。
有機材料的潛力
設備的每一部分都由便宜的有機材料制成。雖然在自然界中找不到這些材料,但是它們大部分都由氫、碳兩種元素構成,而且與大腦化學物質兼容。細胞已經可以在這些物質上生長,並且已經被來打造用於神經遞質(neural transmitters)的人工泵。用於訓練這類人工突觸的電伏也和穿行人類神經元所需的能量相同。
這些都使得人工神經突觸與生物神經元之間的交流成為可能,可借此改進腦機接口。同時,設備的柔軟性與靈活性也使得它可被用於生物環境。但是,進行任何生物學方面應用之前,團隊計劃先打造一列人工神經突觸,用於進一步研究與測試。
原文鏈接:http://news.stanford.edu/2017/02/20/artificial-synapse-neural-networks/
 匿名用戶
匿名用戶
不吹不黑,2017人工智能離我們有多遠?
來源: http://www.iheima.com/promote/2017/0224/161462.shtml

很多互聯網公司都宣稱正在進軍人工智能領域,但產品能否踏實落地才是檢驗成功的唯一標準。
2016年兩個事件讓人工智能(Artificial Intelligence簡稱AI)成為大眾熱議關鍵詞。
一個是AlphaGo掀起的兩次波瀾:第一次4:1戰勝當今圍棋最強者李世石,第二次是化名Master在圍棋對戰軟件中以60戰全勝各大圍棋高手。可以說,AlphaGo團滅了整個圍棋界,震驚了人類世界。
另一個是《西部世界》(West world)。戲中講述的是人類構造了以機器人為背景的遊戲樂園,在遊戲樂園里人類可以為所欲為。當人工智能自我意識覺醒之後,設計師、玩家與機器人之間的矛盾引發了災難。
霍金、比爾·蓋茨、馬斯克等眾多科學界和互聯網領袖,都曾表達對人工智能未來失控的憂慮。事實上,人工智能比我們想象的要複雜。關於人工智能所涉及的學術內容,研究範疇和實際應用產品非常多,完全講透估計得要寫一本書。
這兩年,幾乎所有的互聯網公司都頻繁布局人工智能,收購相關企業。國內的BAT中,百度公開宣布ALL IN 人工智能,阿里和騰訊也在大數據和雲計算服務方面不斷加重投入。其它如語音識別、智能翻譯、無人駕駛、無人機,機器人等企業也在圍繞人工智能開發產品。
當許多公司開始以人工智能作為企業發展方向的時候,實際應用的產品好像並不多,我們難免因此而困惑,他們口中的AI究竟是營銷需求,還是真實的產品?
筆者認為,人工智能的確是被我們低估了。以下,我們從大數據+人工智能、人工智能硬件產品,**這兩個領域講講人工智能的應用場景。
一、大數據+人工智能
場景一:
BAT這種大型企業常用的模式:構建應用場景,收集用戶習慣大數據,然後通過雲計算進行邏輯推理,機器學習之後再優化場景,推送給用戶。這就是人工智能的閉合循環。
大數據從兩個緯度收集用戶數據,一個是足夠龐大的用戶數量,另一個是用戶足夠持續的使用時長。
無論是百度搜索、阿里電商、騰訊的QQ和微信,還是GPS導航、汽車出行、O2O的旅遊和美食、甚至是你身上的穿戴設備,通過構建各種應用場景,企業都可以獲得用戶的相關數據。越是剛需的產品,數據基數就越大,準確性就越強。
場景二:
在《王者榮耀》遊戲中,我們不妨設想:人工智能通過數據知道你習慣使用的英雄,然後匹配其他習慣使用不同英雄的玩家與你搭檔。
同時為了保持平衡,會安排實力相當的對手給你。
當然,如果你取得連勝,會安排更厲害的對手,由此讓你有購買符文沖動。
場景三:
大數據還有更多的想象空間。比如騰訊通過收集你的生活習慣、興趣愛好,做求職網站,結果可能會秒殺所有求職網站。
二、人工智能硬件產品
1、智能家居產品
所有“語音識別+互聯網+軟硬件產品”,將成為這一類人工智能產品的標配。無論是個人電腦、手機、還是智能家居產品。
比如,谷歌的Google Home,亞馬遜的Amazon Echo。這類產品是“人工智能+互聯網”的基礎上,增加了音箱和無線路由器功能。它們將與手機競爭智能家居的核心地位。
通過以上的無線路由器,可以連接你家里的所有智能設備,諸如智能門鎖、智能電視、智能冰箱、掃地機器人......
其它幾家擁有自己人工智能的,微軟、蘋果也必然會推出智能家居的產品。因此智能家居戰場在2017會湧現許多有創意的新產品。
2、無人飛機
大疆無人機的出現,將無人機從玩具飛機、航模飛機,加上航拍系統,成為具備商業和軍事功能的產品。
未來無人機將會被更廣泛地應用於各種商業用途,個人玩家也可以應用於旅遊出行的航拍、甚至旅遊直播平臺。
3、無人汽車
特斯拉推出了SAE L2的自動駕駛汽車Model S,這個級別的系統能夠搞掂大部分的行使操作,包括自動轉動、制動、加速等。但用戶必須隨時留心並對突發情況做好準備。
去年7月,在美國佛羅里達州,一輛Model S在Autopilot自動駕駛模式下,撞上了一輛重型卡車,不幸的車主當場死亡,這起事故成為特斯拉累計2億900萬千米的行程之後的首例致死事故。
2017年,將是智能汽車進入初級階段的關鍵一年。國內的百度和阿里都有布局智能汽車領域,可惜,它們更多是停留在“概念車”。反而是樂視在2017CES大會上,發布的新品電動車FF91,據說將於2018年交車。
4、手機
手機的人工智能,除了我們熟悉的蘋果手機智能助手siri,國內手機品牌也開始擁有自己的手機端AI。
比如華為榮耀去年年底發布的榮耀Magic,就內置了“Magic Live”人工智能系統,將智能用到了人們衣食住行等方方面面。
比如其中一個功能是:當你與朋友聊天,問到“你在哪”或者“你那天氣怎樣”時,榮耀Magic智能識別聊天內容,定位出你的位置或者天氣信息,並且顯示在你的輸入法候選詞首位上。
隨著手機行業的產品同質化嚴重,導致競爭激烈。今年的國內手機廠商將會在系統上花費更多的研發精力,優化系統,讓手機更“懂”消費者,以此提升產品的用戶體驗。
5、機器人
去年12月,美國白宮發布了一份名為“人工智能,自動化和經濟”(Artificial Intelligence, Automation, and the Economy)的報告。報告預計未來十年里人工智能代替人類工作的比例將從現在的9%上升到47%,接近一半。其中最重要的是機器人可以促進經濟發展更有效率。
美國微軟公司創始人比爾·蓋茨甚至認為,如果機器人將大範圍取代人類工作崗位,那它們至少應為此買單。因此蓋茨建議政府向企業為雇用機器人員工而征稅。
工業機器人和企業服務型機器人是當前的主流產品,而C端的個人陪伴、家庭服務、智能家居等領域的智能機器人也將有望在可預期的未來迎來增長。
因此,當無數企業都在瘋狂涉足人工智能領域的時候,誰又能真正引領這個行業快速稱霸呢?
總結:能落地的是NB,不能落地的是SB。
 匿名用戶
匿名用戶
人工智能和機器學習值得關註的6個方向和代表公司
來源: http://www.iheima.com/zixun/2017/0224/161461.shtml

能落地的都是NB,不能落地的都是SB。
本文由IT桔子(微信 ID: itjuzi521)授權i黑馬發布。
人工智能在過去的10年當中取得了長足進步,無論是無人駕駛,還是語音識別、語音合成。在這樣的背景下,AI已經成為一個越來越熱門的話題,並且已經開始影響我們的日常生活。
以下是人工智能發展值得關註的六個領域,對電子產品和服務的未來將會產生巨大的影響。我將解釋它們是什麽、為什麽重要、如何被運用,以及列舉相關技術領域的公司。
01 強化學習Reinforcement Learning
強化學習是機器學習中的一個領域,強調如何基於環境而行動,以取得最大化的預期利益。其靈感來源於心理學中的行為主義理論,即有機體如何在環境給予的獎勵或懲罰的刺激下,逐步形成對刺激的預期,產生能獲得最大利益的習慣性行為。增強學習是機器學習中一個非常活躍且有趣的領域,相比其他學習方法,強化學習更接近生物學習的本質,因此有望獲得更高的智能,這一點在棋類遊戲中已經得到體現。
Google DeepMind 的AlphaGo就采用了強化學習,強化學習另一個典型的應用是幫助優化Google數據中心降溫系統的能源效率,強化學習系統可以將原來降溫的能耗降低40%。使用強化學習技術一個重要優勢是,訓練數據的積累的成本會很低。而監督深度學習技術往往需要非常昂貴的訓練數據,並且是很難從實際生活中獲取。
應用:多個智能體(agents)共享同一個模型,各自進行學習;或者與環境中其他智能體交互和學習;學習三維環境導航,比如迷宮、自動駕駛的城市道路;在學習了一系列目標任務後對已觀察過的行為進一步增強重述。(學習駕駛或者在電子遊戲中為NPC賦予類似人類玩家的行為)
公司: Google DeepMind, Prowler.io, Osaro, MicroPSI, Maluuba/Microsoft, NVIDIA, Mobileye
主要研究人員: Pieter Abbeel (OpenAI), David Silver, Nando de Freitas, Raia Hadsell (Google DeepMind), Carl Rasmussen (Cambridge), Rich Sutton (Alberta), John Shawe-Taylor (UCL) 等
02 生成模型Generative Models
判別模型(discriminative models)主要用於分類和回歸任務,生成模型主要用於在樣本訓練中學習概率分布。
應用:時序信息模擬;超分辨率圖像;2D圖像三維重建;基於小樣本的數據生成;單輸入多輸出系統;自然語言交互;半監督學習;藝術風格轉換;音樂和聲音合成;圖像修複
公司:Twitter Cortex, Adobe, Apple, Prisma, Jukedeck*, Creative.ai, Gluru, Mapillary, Unbabel
03 記憶網絡Networks with memory
為了能讓AI系統具有真實世界一樣的多樣性環境,AI必須持續學習新任務並在未來記住如何處理它們。傳統的神經網絡並不能記住這麽多任務,這個缺點被稱為災變性遺忘(Catastrophic Forgetting)。這是由於當神經網絡從解決A問題轉向解決B問題的過程中,神經網絡會隨之變化。也有很多種強大的網絡結構賦予了神經網路不同程度的記憶能力。包括長-短記憶網絡,能夠處理和預測時序;DeepMind的微分神經計算機結合了神經網絡和記憶系統的優點,以便從複雜的數據結構中學習;同時還有彈性權重聯合算法,根據先前問題的重要性來減慢某些權重。
應用:對新環境有舉一反三能力的學習性智能體(agent);機械臂控制、自動駕駛、時序預測(金融、視頻、物聯網);自然語言理解和預測
公司:Google DeepMind, NNaisense, SwiftKey/Microsoft Research
04 從更少的數據中學習、建造更小的模型
眾所周知,深度學習需要龐大的數據來進行訓練,比如ImageNet的視覺識別大賽,每支隊伍需要識別120萬張1000種類別的人工標註的圖像。如果沒有大規模的數據訓練,深度學習模型無法使用,也無法完成語音識別和機器翻譯這類的複雜任務。
在解決端到端的問題時,單一神經網絡訓練所需的數據量只會越來越多,例如從音頻錄音中識別語音文本。
和使用多個不同神經網絡處理不同人物的組合不同(音頻→發音→單詞→文本輸出)。
如果要讓AI解決一個數據有限、數據成本很高或者獲取十分耗時的任務時,能從小樣本中學習最優解決方法的模型十分重要。用小量數據進行訓練有很多挑戰,一個替代的方法把之前機器學習模型知識轉移到新的模型上,這叫做轉移學習(transfer learning)。
應用:訓練淺層網絡來模擬在大規模數據集上訓練好的神經網絡;與深度網絡模型表現相同、但參數更少的模型;機器翻譯。
公司:Geometric Intelligence/Uber, DeepScale.ai, Microsoft Research, Curious AI Company, Google, Bloomsbury AI
05 用於訓練和推理的硬件
AI發展的一個主要催化劑是將GPU用於訓練大規模神經網絡。訓練神經網絡需要大量的運算量,GPU用於訓練遠遠快於CPU。自從2012年首個使用GPU的深度神經網絡AlexNet出現後,GPU 成為了訓練神經網絡的首選。在2017年英偉達繼續領跑這一領域,而英特爾、高通、超微和谷歌緊隨其後。
GPU最初並不是為了機器學習而制作的,而是用於渲染電子遊戲畫面。GPU計算精度很高,並且不會經常遭遇內存帶寬的限制和數據溢出的問題。有一批專為深度學習定制芯片的創業公司,Google又開發了針對高維機器學習應用的芯片。新型的芯片內存寬帶更高、計算能力更強、能耗更低。提高AI系統運算能力為AI公司和用戶帶來的好處是:更快更高效的訓練模型→更好的用戶體驗→用戶更多使用產品→產生更多的數據→數據幫助優化模型。因此,誰能夠更快、更高效的訓練和部署AI模型,就能擁有巨大的優勢。
應用:快速訓練模型(尤其是圖片領域)、進行預測時的能源和數據效率、運行前沿AI系統(物聯網設備)、隨時可進行語音交互的物聯網設備、雲基礎設施服務、自動駕駛汽車、無人機、機器人。
公司:Graphcore, Cerebras, Isocline Engineering, Google (TPU), NVIDIA (DGX-1), Nervana Systems (Intel), Movidius (Intel), Scortex
06 模擬環境
如前文所述,為AI系統生成訓練數據通常是一個挑戰。而且如果要能在現實世界應用,AI需要概括各種情況。因此,開發模擬真實世界物理和行為模型的數字環境需要能夠衡量和訓練AI通用能力的試驗環境。在模擬環境中進行訓練有助於我們更好的理解AI如何學習、如何改善自身,同時為我們提供了潛在的可以轉換為真實應用的模型。
 匿名用戶
匿名用戶
焦點房產網、拉手網創始人吳波 人工智能時代,誰掌握機器誰賺大錢
來源: http://www.infzm.com/content/123185
吳波(東方ic/圖)
吳波畢業於清華大學自動化系,獲美國西密歇根大學計算機科學碩士。1997年開始創業,前後創辦過7個公司,其中知名度較高的是焦點房產網(賣給了搜狐)和拉手網(賣給了宏圖三胞)。吳波最新一個創業項目是美澳居,在美國做房地產買賣,拿到了DCM等知名風投的投資。
非AI(人工智能)概念的項目將很難拿到投資
我的一些老部下經常問我關於融資的技巧,我跟他們說,如果你的項目不是人工智能概念,就別指望融資了,就算融到錢,項目的可持續能力也很弱。
這不是危言聳聽。我現在每年30%的時間在美國。我看到的情況是,在矽谷,如果一個公司的域名里沒a有“AI(人工智能)”,基本沒有機會拿到投資。這一幕離中國創投圈並不遠。我自己做天使,基本只投人少的公司,這些公司大量使用人工智能技術解決問題。
現在人工智能還處在技術革命的早期。我的判斷是,2018年,智能化趨勢會加速。中國在人工智能方面跟國外有不小差距。現在中國做人工智能的都很自信,甚至有些膨脹。有人說,在人工智能時代,中國跟美國處在同一起跑線,說這話的人要麽是真不懂,要麽是裝不懂。
在美國,人工智能工程師的開發效率差不多是中國同行的三倍。也就是說,中國人工智能工程師開發一個產品,需要的時間是美國同行的三倍。這麽算下來,對中國公司來說,一個人工智能工程師的工資成本,就比美國東部一些城市的工程師成本要高了。
今天的中國互聯網還沒有完全跟國際互聯網接軌,我們的互聯網研發環境跟國外還沒有完全打通。全球人工智能的很多底層技術都在雲端,這些現成的技術成果,目前我們還不能便捷地接觸到。
很多中國互聯網公司,選擇到美國去設立研發總部。這樣他們的研發人員,能直接用到全世界最先進的人工智能程序。相當於站在巨人的肩膀上去研發。
所以我建議,我們應該對某些固定技術點,持更加開放的態度,這樣會幫助到國內的工程師和互聯網公司,讓我們的互聯網在國際上更加有競爭力。
中國有多少人工智能專家?
15年前,中外的互聯網開發環境差距並不大,因為那時候沒有雲端。這10幾年,很多國際先進技術產生了,而且都放在雲端,如果我們不能便捷地觸碰到這些技術,我們在開發環境上跟國外的差距會越來越大。
目前中國在人工智能領域相對有優勢的公司是百度。另外就是一些在特定領域有優勢的公司,比如科大訊飛在語音識別上的優勢。但至少從現在來看,中美在人工智能上的差距並沒有減少的跡象。
如果我們不能站在斯坦福大學和伯克利大學等世界知名學府的人工智能大拿的技術肩膀上,很多基礎程序就要重新寫一遍,這樣怎麽去跟國外競爭?
我女兒在伯克利上學,她告訴我,她們學校的教授,每工作幾年,就可以休息一年。每次這些教授休息的時候,Google會請其中的人工智能專家去公司工作一年,年薪往往是100萬美元甚至200萬美元。
在美國,很多下棋下得好的教授,都被互聯網公司當做人工智能專家請去做開發,年薪都在50萬美元到80萬美元。
中國高校有幾個能被國外互聯網巨頭花如此巨資請去工作的人工智能專家?說句不好聽的話,別說200萬美元,20萬美元都不一定有公司請。
在中國,人工智能專家主要集中在微軟亞洲研究院。人數不多,天天被中國互聯網公司挖來挖去。
智能化管理是大趨勢,人工智能會讓很多人失業
在人工智能時代,組織形態和管理模式會發生變化。一個公司不需要那麽多人了,公司會越來越小。回過頭來看拉手網,如果時光倒流,我肯定不會那麽快速擴張。如果再做一次O2O,我會做一個人少的公司。美澳居現在只有10個人,我們在國外有很多加盟夥伴,他們跟我們的關系,就是司機跟Uber的關系。
最重要的是,人少之後,好管理了,創業者沒那麽累了。智能化管理將是未來一個大趨勢。我們公司很多日常管理都是人工智能在做。比如周報提醒,你不寫的話,機器會自動扣錢。程序是公平的,不需要管理者再去扮演“醜人”角色。我只當好人,比如有人覺得機器太無情了,來向我求情,我可能就給他們一個豁免。
人工智能會幫我們替代掉很多需要人工的職位。比如,人工智幫我們監督建築成本。一塊地磚的成本,計算機比人記得要清楚的多。
在人工智能時代,公司應該是越來越專。就像挖井一樣,你想挖到油,不能挖一個操場那麽大的井口,你得往深了鉆。
未來一個公司是否掌握或能否使用人工智能技術,決定了這個公司是否有核心競爭力。
對創業者來說,最好選擇人工智能領域創業。如果不在人工智能領域,那也要避開很多更新周期太快的行業。比如最好別選電子和手機行業,這兩個行業的產品三到六個月就更新一次,創業者壓力太大。但如果選房地產行業,一塊地磚的生命周期是六七年。我的建議是,創業者最好選擇跟傳統行業有結合的行業,這樣能更長久一點,也更容易做起來。
如果你用假數據餵養機器,很容易把機器餵傻
我們也是最近一年才感覺到人工智能的威力。
剛開始,我們買地主要是靠當地的地產中介。他們幫我們找地。一塊地的交易額往往是幾百萬美元,如果中介從中暗箱操作,賺走我們50萬美元是很有可能的。
所以我們買地的時候,堅持自己去實地查看,要不然心里沒底。但即便這樣,我們人工判斷的土地,超過一半最後證明是虧本的。
後來我們嘗試開發了一套智能土地系統,幫我們尋找有升值潛力的土地。最初的時候,系統推薦的土地我是很不看好的,都是一些蠻荒之地,按常理很難升值。但沒過多久,這些土地真的大漲,因為系統知道的數據比我們要全、要準、要快。所以後來我們在買地的時候,就主要聽系統的建議,基本上百發百中。
過去買地,要依賴中介,因為他們對小區熟,對房子熟。但其實中介知道的很多信息,網上都是公開的。通過技術來抓取和解析這些數據後,變成了一個電子大腦。我們在不同地區,有不同的電子大腦,電子大腦正在替代很多行業的中介職務。
人工智能的基礎是大數據。有足夠多數據才能有人工智能。現在很多中國企業都說自己的大數據很牛,但其實跟國外差距還是很大。
最主要是兩點。一是中國企業的大數據是相互不開放的,或者說只在一個大的巨頭生態體系內實現了數據共享;二是很多中國企業掌握的數據是假數據。人工智能是吃數據長大的,不斷對知識數據進行重複學習。如果你用假數據餵養機器,很容易把機器餵傻。這樣的人工智能技術能有什麽競爭力?
人工智能的核心是算法,它很難去外面買到,只能自己做。未來誰能找到更多的人工智能專家,誰的企業就更容易勝出。
智慧大腦讓人實現另類“永生”
以後每個人都可以將人工智能為己所用。理論上說,每個人都有自己擅長的知識點,未來借助人工智能技術,你可以把這些知識點,收集在一個外設計算機知識庫里。這是你專屬的人工智能知識庫。它可以開放給其他社會成員。別人進入這個知識庫,問你一個問題,就能聽到你自然語音甚至是帶口音的回答。
馬斯克(特斯拉創始人)說,人類最大問題是輸入和輸出處在串行狀態。在人工智能時代,馬斯克的擔憂將不複存在。這個知識庫可以讓你同時跟無數人溝通,實現人類輸入和輸出信息的並行模式。
這個知識庫將變成人腦的輔助大腦。它會自我進化和完善,變成智慧大腦。以後你的智慧大腦可以是一個很好的商品。購買你的智慧大腦服務的人,可以從你這里學到很多東西,比如如何進行職業轉型?往哪里轉?有了這個超級知識庫,你就變成了超級網紅。
每個人只能活一輩子,但你的智慧大腦會被傳承下去。某種程度上,你通過智慧大腦得到了“永生”。幾百年後,你的後人還能通過你的智慧大腦,跟你自然交流,就像你們面對面坐在一起一樣。
一定要讓你的孩子從事創造性工作
隨著人工智能的發展,未來很多人會失去工作。在矽谷,很多人正嘗試用人工智能給人治病。比如癌癥治療。在美國,很多人工智能技術已經開始替代專業醫生,比如放射科醫生。這些醫生的年薪一般都在40-50萬美元。一臺機器可能很貴,但多替代幾個醫生,成本就抵消了。所以很多醫院願意使用人工智能機器。在醫療界,機器正在讓那些剛畢業2年的博士失去工作,因為他們的工作被替代性最強。
下一步機器將在服務業被大量使用。尤其是在西方,很多人不屑於從事服務業,機器的替代會更快。在亞洲,機器對人的影響要慢一點,因為亞洲人更樂意從事服務業。
對個人來說,在人工智能時代,一定要讓自己的孩子從事創造性工作,只有這樣才不容易被機器替代。
人工智能也帶來很多社會問題。它提高了政府治理的能力,但當技術跟政治結合越來越緊密之後,技術對社會發展的影響會進入更深層次。
未來的有錢人將是那些掌握機器的人。他們用機器代替了九成以上的工作機會,把九成人的錢都賺了。有錢人掌握機器後,會更有力量,所以有可能在未來帶來新的社會矛盾。
人工智能搶你的飯碗了嗎?HR如何逆襲成功?
來源: http://www.iheima.com/zixun/2017/0228/161541.shtml

人工智能的機器人很有可能搶走HR的飯碗。
本文由世界經理人(微信ID:CEC_GLOBALSOUERCES)授權i黑馬發布。
最近一則消息讓許多HR驚恐萬分。日本高端人才招聘網站BizReach與雅虎和美國客戶管理平臺salesforce.com合作,宣布將開發一種人工智能,通過收集員工的工作數據,完成招聘、員工評價和分配工作崗位等任務。在不遠的將來,具有人工智能的機器人很有可能搶走HR的飯碗。
《世界經理人》最新的相關調研結果顯示,大多數的中國制造企業目前仍然處在基礎性事務性工作為核心的人力資源管理階段。而基礎性事務性的HR工作最容易被人工智能所取代。不論是為企業的發展,還是為HR的職業發展著想,都需要向更高的人力資源管理階段升級,在這樣的階段,HR被要求扮演更重要的支持企業戰略發展的角色。
這項“中國制造業人力資源管理現狀調查”在2016年11月至12月間完成。參與此項調查的是230多家制造企業的董事長、總經理、副總經理,以及人力資源部門的總監、經理和專員。在行業分布上,電子制造業和機械制造業各占14%,占比最高。
人工智能威脅HR
在此次調查中,九成以上被訪者認可人工智能將取代HR的一些工作,其中48%的被訪者認為,未來十年中,小部分HR基礎性、事務性工作將被人工智能取代;46%的人認為,大部分HR基礎性、事務性工作將被取代(參見圖1)。

隨著人力資源管理職能的發展,以及移動互聯網技術的進步,絕大部分的基礎性、事務性工作會被機器或人工智能替代,將人力資源管理者從事務性工作中解放出來,這釋放出積極的意義。戰略咨詢專家、中和正道管理咨詢公司執行總裁吳玉光指出,人力資源管理的核心競爭力並非基礎性、事務性的工作,而是在企業總體戰略框架下對人力資源進行使用、管理、控制、監測、維護和開發,籍以創造協同價值,達成企業戰略目標的方法體系,而這也是任何機器和人工智能無法替代的。

雖然隨著中國制造2025規劃的實施,未來中國制造業將逐步實現機器直接取代人工制造和生產的模式,但就算這一天來臨,“人”依然是企業的主體和根本,如何管理“人”才是企業進步和發展的關鍵所在。如何專註人力資源核心業務,盡快讓自身能力和競爭力增值,成為制造業大多數HR工作者刻不容緩的課題。
績效管理現狀不如人意
從調查數據中可以看出,大多數制造企業已經使用績效管理來提升個人、部門和組織的績效。可喜的是,不少企業的員工在工作中能夠獲得上級的有效支持與指導,獎懲與績效結合緊密,且力度大。但是整體上看,幾個關於績效管理的問題的得分基本集中在2分和3分,績效管理還有很大提升空間(參見圖2)。

吳玉光指出,調研數據和管理咨詢實踐中的感覺非常一致,在人力資源管理最基礎、最核心的績效管理領域,制造企業實施的效果並不理想。也就意味著絕大多數的中國企業還需要在人力資源管理的基本功方面多下力氣,而不能被眼花繚亂的概念或者名詞搞暈了自己。管理本身是有其規律和規則的,管理創新要圍繞基本的管理要素展開才是有價值的。
基於戰略的績效管理是一個複雜、細致的工作,既與企業戰略的制定相關聯,又涉及到企業每一位員工的具體工作,同時與企業的文化、人員素質等有著密切的關系。吳玉光提醒,制造企業在做戰略績效管理時,應該將正激勵與負激勵有機結合在一起,從目標的制定、過程的評估和激勵,對人的行為產生正向的引導,使績效管理形成閉環。
在華為,員工的發展和其個人績效有著密切的聯系,只有績效優秀的員工才有機會進一步發展,績效差的員工則被淘汰。績效考核結果幾乎成為了員工在華為立足、得到發展的唯一依據,也是這種文化,促使員工在工作中不斷尋求改進、努力提高自己的工作效率和工作質量,從而提高績效水平,最終得到長足發展。
在績效考核管理的六個維度中,“為員工的能力提升提供詳盡指導”此項的數據明顯低於其他項,說明目前制造企業各級管理者尚未將員工的成長放在重要的工作內容中。員工只有能力不斷的獲得了提升,才能為企業創造出價值,從而更好地做出業績,走向優秀和卓越。。在知識經濟時代,這一點顯得尤為重要,因為員工都知道在企業里如果能力沒有得到提升,即使在其他方面獲得再多,也不能保證以後會有長遠的發展機會。
針對這些不足,企業的HR部門應該對中高級管理者進行有效的教練式領導力培訓,提升其績效溝通能力和培養意識,才能真正發揮績效管理的作用和價值。
人力資源參與戰略決策
今天,當制造企業直面全球化競爭的挑戰,企業戰略調整之後,公司的人才結構、薪酬體系、招募方法、培訓需求也相應變化,以支撐戰略調整的順利實現。在這個員工自主意識不斷加強的時代,制造企業的HR部門應該如何應對這些挑戰?
從調查數據可以看出,僅有兩成企業已經跨入戰略性人力資源管理階段。這說明中國大多數的企業還需要繼續練習管理基本功。在做“人、產品、市場”重要性排序的選擇題時,大多數制造企業老板把產品或市場放在第一位,不重視“人”的管理,這也是制造企業人力資源管理能力低下的原因之一。人才是企業最核心的競爭力,如果一個企業的人力資源管理長期處於這種狀態,勢必要在殘酷的市場競爭中被無情淘汰(參見圖3)。


超過七成制造企業的人力資源部負責人很少參與公司戰略的制定(參見圖4)。吳玉光指出,造成這個現狀有多方面的原因,一方面是企業戰略制定的高層決策者沒有這樣的意識,對人力資源工作重要性缺乏必要的認知,另一方面因為絕大多數HR負責人對公司業務理解不足,缺乏參與戰略決策制定的必要能力。

解決這個問題的關鍵,不僅要依賴最高決策者的戰略意識轉變和戰略管理能力的提升,更重要的是,HR負責人應該主動了解企業各項業務的發展進程,深入了解其需求,將業務面臨的挑戰不斷轉化成他們對HR的需求,再想辦法去解決問題。只有充分了解企業的戰略目標和需求,盡早參與進去,HR才能體現其價值和能力。
英國石油(British Petroleum)燃油及潤滑油技術部全球人力資源總監宮瑞萍在采訪中告訴記者,她在戰略會議上聽取業務部門負責人談新的業務目標時,會不斷思考新業務將需要具備哪些專業技能的人才,現有的內部人才結構有哪些差距,如何才能獲得這樣的人才。當戰略會議討論之後,HR的解決方案已經有一半已經完成。之後她會考慮新方案如何以最低的成本實現,對現有人才可能有哪些沖擊,目前需要花高價去市場引進怎樣的特別人才,但長期來看,這樣的特別人才從內部如何來調配和培養。只有這樣,才能使得HR部門成為業務部門戰略制定與戰略執行的合作夥伴。
戰略調整對HR形成挑戰
企業的戰略調整一般是指戰略方向或者戰略重點、戰略目標的變化。這種變化將導致組織結構、績效管理指標、激勵機制和領軍人物的調整,這幾個方面的調整恰恰是戰略轉型實施的關鍵。成功調整到位的話,戰略實施也就比較順理成章,變革轉型的阻力就會大大變小。從調查數據來看,激勵機制的重新設計是戰略調整給HR帶來的最大挑戰,其次是適應新戰略的薪酬方案設計、招聘到符合戰略需求的高端人才,四成的調研參加者認為戰略調整後,企業的人力資源管理、開發體系不適應人才需求的變化,應該進行升級(參見圖5)。

吳玉光認為,組織結構的調整主要涉及到戰略導向、業務屬性、管理文化、領導風格等多方面的因素,是屬於董事會的關鍵事項之一,只不過在很多時候被董事會忽視而已。其他幾個方面的工作,包括激勵機制與績效管理,以及關鍵人才選拔都需要慎重對待,合理進行布局,才能有效的幫助各部門把戰略轉型的路線圖轉化為各個部門人員的一致性行動。
華為成功的關鍵因素是嚴格地按照企業戰略規劃目標,制定戰略性人力資源規劃,並大規模進行相關人才儲備。面對日趨激烈的人才競爭環境,每一個企業都有各自不同的戰略目標,都需要一套完全屬於自己的戰略性人力資源規劃。
當被問到“理想中HR部門能夠承擔哪些責任?”時,建立高效的人才選拔體系、支持企業戰略目標的實現、支持企業形成強大的企業文化排在最前列。從中可以看出,參與問卷調查的人員對於人力資源管理的使命、定位還是比較清楚的,也就是希望HR在企業發展過程中扮演越來越重要的角色,承擔更大的責任(參見圖6)。

從整體調查結果來看,目前大多數制造企業的人力資源管理的現狀並不樂觀,離業務部門的“戰略合作夥伴”還有很大差距。吳玉光認為,HR負責人應該主動作為,增強自己在公司決策過程中的影響力,通過其專業能力的提升來贏得公司決策層的信任,改變決策層的認知,從而實現人力資源管理在公司頂層設計中的重要使命。
 匿名用戶
匿名用戶
人工智能還會賣菜,零售界的Uber如何顛覆你的菜籃子
來源: http://www.iheima.com/zixun/2017/0301/161589.shtml

從簡單的搬運工變得更高效,Instacart或許可以為國內的同行們提供一些參考。
美國零售電商Instacart創辦於2012年,僅僅用了兩年多的時間做到估值20億美元,如今,Instacart的創始團隊又借助數據科學( Data Science)和機器學習(Machine Learning)幫助企業優化運營,實現正現金流並逐步走向盈利。
從簡單的搬運工變得更高效,Instacart或許可以為國內的同行們提供一些參考。
模式:不僅僅是零售商的搬運工
Instacart是自身不做采購倉儲的在線零售商,Instacart與美國著名的零售商合作,把這些零售商的商品搬到線上銷售,其中包括Whole Foods、Costco、Marsh等知名連鎖零售商。消費者可以通過電腦或者手機App下單, 然後由Instacart簽約的代購者(Shopper)去指定的商店采購,在1小時內配送到消費者家中。
下圖是消費者用手機App購物的流程:

Instacart的代購者(Shopper)很像Uber的司機,他們可以是全職也可以利用閑散時間兼職。下圖是一個代購者 用App接單並完成訂單的流程:

單元經濟盈利:打破燒錢魔咒
對於這種創新的商業模式,能否盈利是最根本的問題。而早在2016年,Instacart就已經實現單元經濟效益(Unit Economics)盈利。
所謂單元經濟效益(UnitEconomics),是指在商業模型中, 能夠體現收入與成本關系的某個最小運作單元。在Instacart,這就是來自客戶的每一筆訂單,如下圖所示,在這每一筆訂單中,能夠帶來的收益有四類:送貨費、小費、產品合作方、零售合作方,而每一筆的成本來自:交易費(信用卡和保險)、購物時間和送貨時間。如果能壓縮購物時間和送貨時間,那麽,Instacart就能在單元經濟效益上盈利。

在 Instacart的單元經濟效益模型中,只要平均完成訂單時間在最大時間的70%就可以盈利,如今他們已經實現了這個目標,Instacart在2016年中實現了正現金流,並預計2017年會實現財務盈利。
精準預測的重要性
要實現盈利以及企業的良好運營,精準地預測客戶需求,並且滿足客戶需求顯得尤為重要。
Instacart每天要應對來自消費者數以萬計的訂單,這些訂單都需要在客戶指定的時間完成配送,如何把這些訂單分配給同樣數以千計的代購者,每個代購者接哪些訂單,走什麽線路去指定的零售店,在每個零售店又如何快速尋找到指定的產品,采購完後,走什麽線路去配送給每個消費者……這些都需要精準的預測和規劃。

(圖示:Instacart為代購者優化後的超市采購線路圖)
Instacart必須要為自己的預測準確率負責,如果預測準確率低,那麽結果就是客戶的訂單延誤,這不僅僅會造成履單成本的提高,也會讓客戶不滿意並造成客戶流失。
機器學習幫助提升
為了應對這些挑戰,Instacart選擇了利用數據科學(Data Science)和機器學習(Machine Learning)。
第一步,是建立大數據平臺。在Instacart,每天要處理和應對的是來自多方面的海量數據,比如,僅僅代購者每天的GPS定位信息就有1GB左右。Instacart要把這些數據分類部署,然後用RabbitMQ來處理各個數據庫之間的通訊,用PostgreSQL做生產數據庫,用Amazon Redshift做離線數據分析。
Instacart會建立多種預測模型來對客戶需求、超市購物時間、配送時間等進行預測。每個模型都會用歷史大數據進行回顧測試,去不斷的優化算法。模型每天做重複的訓練來提高預測的準確率。
當遇到惡劣天氣或突發事件時,會有偏離模型的警告,Instacart有一個監測市場變化的團隊,他們會在這個時候用自己的接口對預測進行調整。Instacart的數據科學團隊正在努力實現調整部分工作的自動化。
梯度推進模型優化配送預測時間
梯度推進模型GBM(Gradient boosting)是一種機器學習的技術,該技術可以提高現有預測模型的準確率。
比如, 在舊金山地區的Instacart辦公室,要在幾個小時之內完成數千個客戶訂單,那麽,如何給出一個最優化的方案,用最少的人力和時間去完成這些訂單呢?顯然需要更精確地去預測每個代購者每條可能路線的時間。此時,GBM模型就非常有用。更精準的預測可以讓系統用優化算法得出最優的完成訂單方案,這個方案可以比以往更快地完成客戶的訂單。
自然語言處理(NLP)提升用戶體驗
自然語言處理NLP(Natural Language Processing)實現人與計算機之間用自然語言進行有效通信的方法。在這里的用處就是分析用戶以往的采購行為,然後給用戶推薦可信的熱賣單品。
Instacart與全美數百家零售商合作,商品匯總起來,數量竟有數百萬之巨。這些產品的訂單頻次分布是長尾分布,那麽如何能夠給用戶推薦那些他們真正需要而不僅僅是熱賣的單品呢?Instacart 用NLP技術去歸納總結,然後推薦那些即使不常被購買但是對客戶有用的商品。比如某個用戶經常購買啤酒、奶粉、尿布和遊戲產品,那麽系統或許會推薦一本《一個奶爸的自我修養》給他。
也玩深度學習
Instacart也用到了深度學習(Deep Learning)技術,比如產品目錄團隊使用深度學習來進行圖片處理,以及代購者在商場某處,重新安排代購清單和線路。深度學習技術解決了以往機器學習中的很多棘手的問題,這為提升服務帶來了新的機遇。
最後,我們來看美國著名科技媒體TechCrunch對Instacart的采訪視頻,看看他們每天是如何快速處理和完成來自客戶數以萬計的訂單:
https://v.qq.com/x/page/j0377e9vska.html
 匿名用戶
匿名用戶
人工全港排第幾?
早兩日在HK01看到一篇全港打工仔都會關心的新聞,作為打工仔的我當然也注意,這是有關香港打工仔的工資分佈。一般來說,讀者多會以10秒內看完這篇新聞的圖表,得個「知」字就算,不過看了看,令我想起往事。
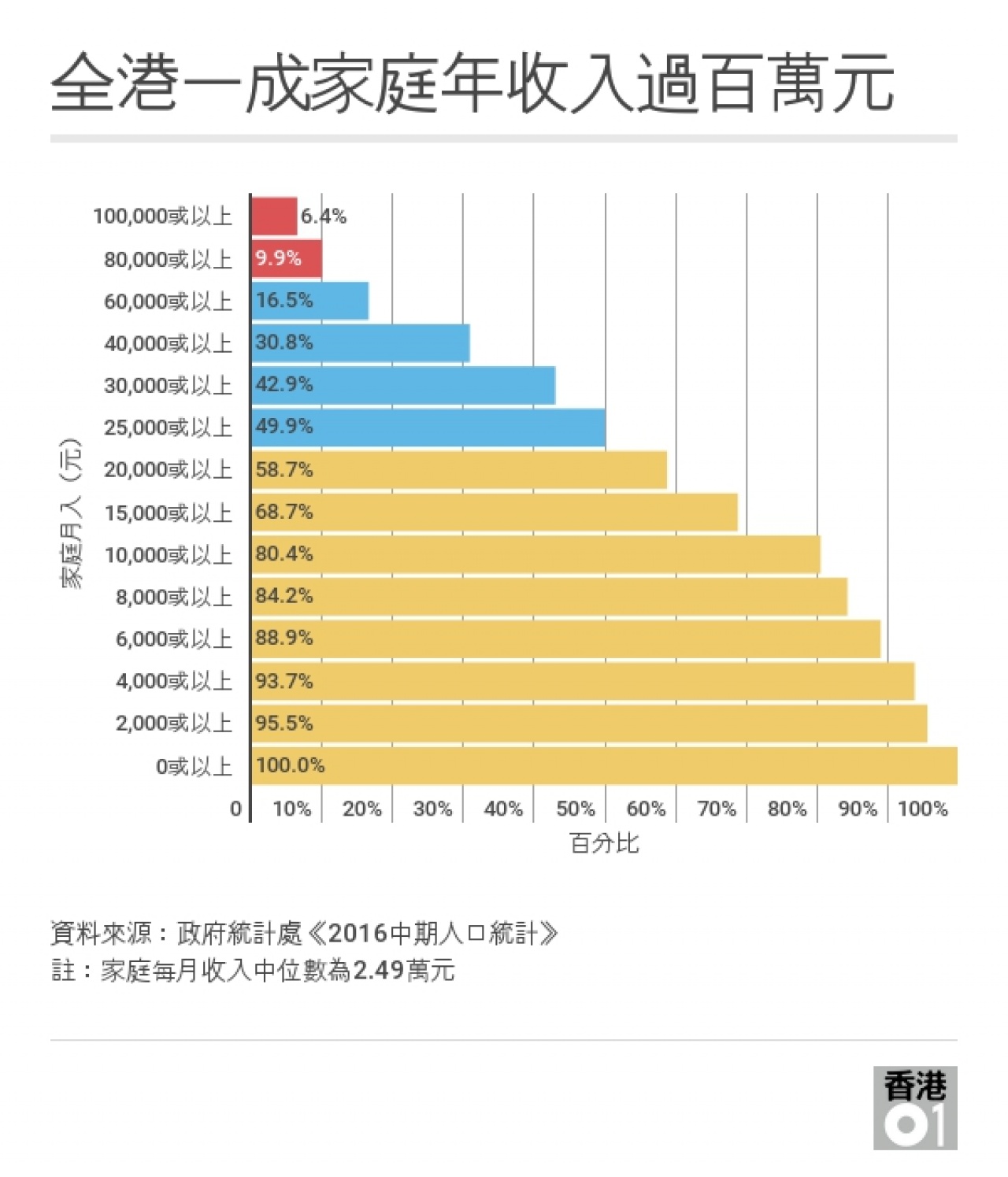
先總結一下新聞內容,根據政府統計處最新數字,現時全港有大約340萬名打工仔,個人收入中位數由2006年的1萬元上升至2016年的1.55萬元。
2015年八大畢業生平均入職月薪為1.34萬至2.19萬元,數字包括醫科、教師等專業,即大部分大學畢業生首份工作月入,已排名在全港打工仔的中間位置。
現時全港有超過23萬人月入6萬元以上,是全港月入最高的6.8%。另超過4萬元計算,佔全港打工仔排首14%。
若以家庭收入計算,入息中位數大約為2.5萬元,收入最高的10%大約為8萬元,而月入超過10萬元的已經是最高的6.4%。
多年前曾經與一位朋友討論人工問題,當時他與太太同為政府的專業人士,以政府薪金點計算,兩口子三十出頭,加起來的人工已經超過每月十萬元,有趣的是他還自以為人工很低。相信這是他的個人觀感,始終作為政府內的專業人士,他算是最年輕的一群,日見夜見的都是比自己高職位或高年資的同事,自然有錯覺認為自己是人工「較低」的一群。
當時這位朋友與太太兩口子,每年賺百多萬元,而未有小朋友,是打工仔之中的DINK(Dual Income, No Kids),現金流超強,有車有樓,生活已經非常好。可惜每天仍在訴苦,指自己乃是普通打工仔,算是中產之中的低下層,或許他們認識的都比自己「好景」吧。
曾經又與另一位朋友談論她女兒的讀書問題,她指雖然不久前升職加人工,但生活反而更辛苦,主因是女兒剛讀N班,報讀的是私校,每個月學費需要五千多元,還有不少雜費等,指自己絕對不是高人工的一群,因此才過得這麼辛苦。
我大概知道她的人工吧,可能有三萬多元,她先生也有工作,收入應該不比她少。當時我問她為何感到辛苦又要讀五千多元的學校呢?她直指這根本不貴,這些學校已經是她這些「窮苦」家庭的小孩讀的了。
我追問:「你窮?你知否今天香港的入息中位數是多少?你的收入大概在香港打工仔中排在哪個位置?」,她回答:「我想。。。中位數應該大概三萬多元,我應該在中間偏低吧。」
好明顯她不太清楚自己的人工水平如何,當時我指香港打工仔的入息中位數大約1.4萬元,如果按她與丈夫加起來的家庭收入也感吃力的話,真正的草根階層的小朋友豈不是沒法子讀書與生活?或許她出身中產家庭,今天又是專業人士,可能自出娘胎都不太了解什麼是窮。
曾聽到有blogger描述年薪百萬的打工仔不算什麼,似乎街上招牌跌下來也會壓死好幾個,或許日常工作見到不少這些人,單是我工作周遭都可能有一百幾十個,但其實這都已經是打工仔中入息最高的5%左右。當然,如果以340萬名打工仔計一計,這5%也有17萬人,所以不少人的確有機會經常被這17萬人圍繞,誤以為這個收入水平是香港的「中位數」。
當然,這只是在討論打工仔的主動收入,沒有談及資產累積與被動收入,亦沒有談及非打工仔的收入,所以反映不了香港人財富累積的情況。然而,雖說香港有錢人多的是,不用打工的有錢人又會很多,不過看數據,打工仔仍是香港的大多數人,一億幾千萬以上身家的人口,比例上絕不會多。要了解全局,就要依數據,否則終日鑽進富豪堆中就永遠以為自己是全世界最窮的一個,會有點奇怪。
多年前,曾經在此討論過財務自由的數字,舉例五十萬元被動收入作為討論前提,隨即被blog友指這是一個不切實際的數字,因為blog友認為五十萬元並不足夠生活。例如生了兩個小朋友,讀書、興趣班、換車、旅行、工人、照顧老人家等等,這已經未有包括小朋友就讀國際學校或外地升學之類。
當時我指財務自由所需的財務水平人人不同,但提醒一點,五十萬元這個數字,很多家庭連主動收入也不達標,按今天的數字,家庭月入4萬元以上已經是最高的三成人口了,或許我們可以分清楚「需要」與「想要」的東西。
多看現實情況,可更「貼地」地分享如何「離地」,其中感覺最離地的blogger之一,Starman兄,不止他個人背景離地,他分享的blog友問答內容也十分離地,似乎全香港收入最高的1%至2%的人都跑去請教他,看多了,實在感覺自己變窮了,哈哈。
相關連結:
https://www.hk01.com/sns/article/74664
Next Page